How a Mobile App Kills Losing Ad Campaigns Before They Finish Their First Day
A mobile subscription app stopped waiting days to spot losing campaigns. Now it knows in hours — and the bad spend stops itself.
A mobile subscription app connected its Meta, Google, and TikTok ad accounts to Mindra and asked it to build a model that predicts, from the first 24 hours of spend, whether a campaign will hit its cost-per-install target. The result: 60% of new campaign tests now get auto-paused or flagged within a day, and wasted spend on campaigns that miss target dropped 22%.
Key takeaways
- The job kept getting squeezed. Three ad platforms meant three dashboards and hours of manual reconciling — so deciding what to scale, kill, or build next never got the time it deserved.
- Losing campaigns ran 2–3 days before anyone caught them. Nobody could check granular performance hourly across three platforms. The money was already gone by the time a human noticed.
- Mindra found the early signal. Six months of historical data showed early click-through rate plus Day-1 retention plus auto-renewal-off rate predicted eventual return on ad spend better than anything else.
- The decision moved earlier. "Campaign launches" to "we know if it's working" compressed from days to hours. Savings come from stopping bad spend sooner — not spending less.
- Humans still decide what matters. Auto-pause only fires under a pre-agreed budget threshold. Anything bigger gets a recommendation and a one-click human approval.
- The scoreboard: 22% less wasted spend, same-day creative briefs instead of a multi-day reactive cycle, and three platforms reporting into one daily view.
Why is running ads on Meta, Google, and TikTok at once so hard for a small growth team?
This app runs paid user acquisition across three platforms at the same time. Meta, Google, and TikTok. Each has its own dashboard, its own reporting cadence, its own quirks.
That sounds manageable. It isn't.
The growth team's real job is to make three decisions, fast and often: what to scale, what to kill, and what creative to build next. Those are the decisions that actually move the business.
But the real job kept getting squeezed by the busywork around it. Logging into three dashboards. Pulling three sets of numbers. Reconciling them into one view that made sense. By the time the spreadsheet was current, half the day was gone and the decisions still hadn't been made.
Two things broke as a result.
First, underperforming campaigns ran for 2–3 days before anyone caught them. Not because the team was careless — because nobody has time to check granular performance hourly across three platforms. A campaign would quietly burn budget while the team was heads-down reconciling yesterday's numbers.
Second, creative went stale. Briefs for the design team were written reactively, days after a trend had already started fading. By the time a "new" concept hit production, the market had moved on.
The pattern underneath both problems is the same: every important decision was happening too late.
What did the setup look like?
The fix didn't start with new software to learn or an engineer to hire. It started with one sentence.
Think of Mindra as hiring a growth analyst who watches all three ad platforms 24/7, never gets tired, and never needs you to copy-paste numbers into a spreadsheet. You connect it to your tools, give it your goals, and tell it what you want done.
Here's what the team did:
- Connected all three ad accounts — Meta, Google, and TikTok — directly to Mindra. No more logging into three dashboards.
- Gave Mindra the benchmarks as standing context. Target CPI (cost per install — what you'll pay to get one new user). Payback period (how long until a user's spending covers what you paid to acquire them). Day-7 retention (the share of users still active a week after install). These numbers became the yardstick Mindra measures every campaign against, automatically.
- Asked it to build a predictive early-warning model. Not a report. A model that calls the outcome before the outcome is obvious.
The prompt was plain English:
"Look at our last 6 months of campaign data. Build a model that predicts, from the first 24 hours of spend, whether a campaign is likely to hit our CPI target. Flag anything that looks like it's going to miss."
Mindra ran the six months of historical data through detailed analysis. It found that early CTR (click-through rate — how often people who see the ad actually tap it) combined with Day-1 retention and auto-renewal-off rate (how many new subscribers immediately switch off auto-renew) was the strongest predictor of how a campaign's ROAS would end up.
Then it built a scoring rule that flags new campaigns as "at risk" within the first 24 hours of launch — before there's enough data for human eyes to flag it.
What did Mindra actually build?
Four things, working together.
1. A cross-platform spend dashboard. Every morning, Mindra pulls spend, CPI, and retention-adjusted ROAS from all three platforms into one unified report. The three-dashboard ritual is gone. One view, ready before the team's first coffee.
2. Early-warning auto-pause. New campaigns get scored against the predictive model within their first 24 hours. Anything flagged high-risk for missing CPI gets surfaced with a one-click pause recommendation. For low-stakes test budgets under an agreed threshold, the pause happens automatically — and is reported after the fact, so the team always knows what moved and why.
3. A creative briefing pipeline. When a specific ad concept or hook starts outperforming on any platform, Mindra automatically drafts a creative brief — what's working, why, and a suggested next variation — and drops it into the design team's Slack channel the same day. No waiting for the weekly sync.
4. A weekly budget reallocation report. Mindra recommends how to shift budget across the three platforms based on blended CPI and retention trends. Critically, it flags when one platform's cheaper-looking installs are actually offset by weaker downstream retention — the cost advantage that isn't really there.
Here's a sample of the morning alert that does the heavy lifting. Present it as a snapshot, not a live feed — your real numbers will differ.
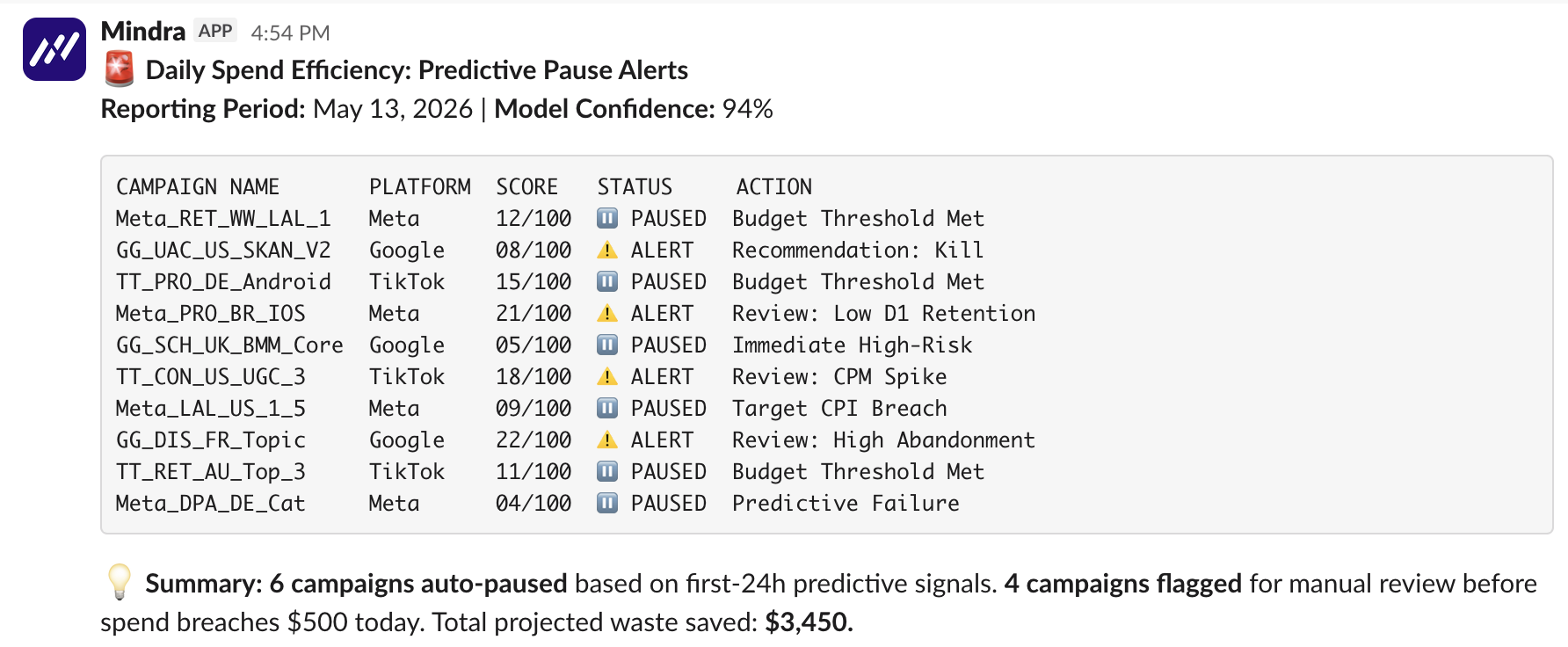 Predictive pause alerts: every new campaign scored within 24 hours, with low scorers auto-paused before they burn a full day's budget.
Predictive pause alerts: every new campaign scored within 24 hours, with low scorers auto-paused before they burn a full day's budget.
Daily Spend Efficiency: Predictive Pause Alerts May 13, 2026 — Model Confidence: 94%
| Campaign | Platform | Score | Status | Action |
|---|---|---|---|---|
| Meta_RET_WW_LAL_1 | Meta | 12/100 | PAUSED | Budget Threshold Met |
| GG_UAC_US_SKAN_V2 | 08/100 | ALERT | Recommendation: Kill | |
| TT_PRO_DE_Android | TikTok | 15/100 | PAUSED | Budget Threshold Met |
| Meta_PRO_BR_IOS | Meta | 21/100 | ALERT | Review: Low D1 Retention |
| GG_SCH_UK_BMM_Core | 05/100 | PAUSED | Immediate High-Risk | |
| TT_CON_US_UGC_3 | TikTok | 18/100 | ALERT | Review: CPM Spike |
| Meta_LAL_US_1_5 | Meta | 09/100 | PAUSED | Target CPI Breach |
Summary: 6 campaigns auto-paused on first-24h predictive signals. 4 flagged for manual review before spend breaches $500 today. Total projected waste saved: $3,450.
Read the scores like a confidence dial: 100 is "on track to hit CPI," 0 is "this is going to lose money." Anything in the single digits gets stopped. Anything in the teens or low twenties gets a human look. The low scorers got paused before they could finish burning a full day's budget.
Why did this work when manual checking never did?
Three reasons, and none of them are "the AI is smart."
It moved the decision earlier. This is the whole game. The savings don't come from spending less — they come from stopping bad spend sooner. When the gap between "campaign launches" and "we know if it's working" shrinks from days to hours, every losing campaign costs a fraction of what it used to. Same decisions, made earlier, with most of the waste cut off at the front.
It treated creative as a live feedback loop, not a quarterly project. Same-day briefs keep the design team working on what's happening in the market now — not what was working last week. A winning hook gets a follow-up variation while it's still winning, instead of after it's cooled off.
It kept humans deciding on anything that mattered. Auto-pause only fires under a pre-agreed budget threshold — small test bets the team already agreed it's fine to kill on a strong signal. Anything bigger gets a recommendation and waits for a human click. The team didn't hand over control. They handed over the busywork and kept the judgment.
How does this compare to the old way of running ads?
The shift is less about tooling and more about when the work happens.
| Before Mindra | With Mindra | |
|---|---|---|
| Catching a losing campaign | 2–3 days after launch | Within the first 24 hours |
| Daily reporting | Log into 3 dashboards, reconcile by hand | One unified report, automatic |
| Pausing waste | Manual, after the budget's mostly spent | One-click recommendation, or auto-pause under threshold |
| Creative briefs | Reactive, days after a trend fades | Same-day, while the trend is live |
| Budget reallocation | Gut feel, based on surface CPI | Weekly, based on blended CPI + retention |
| Who decides | The team, when it finally has time | The team, on everything that matters — instantly |
What did the scoreboard say?
After putting the model to work:
- 60% of new campaign tests are now auto-paused or flagged within 24 hours based on the predictive model.
- 22% reduction in spend wasted on campaigns that ultimately missed the CPI target.
- Creative brief turnaround dropped from a multi-day reactive cycle to same-day.
- 3 ad platforms now report into a single daily view.
Notice the team didn't grow. The headcount that used to drown in reconciling three dashboards now spends its time on the decisions that actually move the number.
What's next for the app?
Two things.
First, feeding post-install retention data back into the model on an ongoing basis, so the early-warning score keeps recalibrating against the latest cohort behavior — instead of relying on a single one-and-done training pass. The market shifts; the model shifts with it.
Second, building campaigns directly inside the platform from scratch, rather than treating Mindra as an add-on bolted onto the existing workflow. From watchdog to operator.
Frequently asked questions
Can AI predict if an ad campaign will fail in 24 hours? Yes. By analyzing patterns in your own historical campaign data — early click-through rate, Day-1 retention, and early subscriber behavior — an AI agent like Mindra can score a brand-new campaign against your CPI target within its first 24 hours of spend, before there's enough data for a human to spot the problem manually. In this case, 60% of new tests are caught or flagged within a day.
How do you cut wasted ad spend automatically? You set a target CPI and a budget threshold you're comfortable auto-pausing under. Mindra scores each new campaign in real time and, for low-stakes test budgets, pauses anything predicted to miss the target — then reports what it did. Larger campaigns get a one-click pause recommendation instead. The savings come from stopping bad spend early, not from spending less overall. This app cut wasted spend 22%.
Can AI manage Meta, Google, and TikTok ads in one place? Yes. Mindra connects to all three ad accounts and pulls spend, CPI, and retention-adjusted ROAS into a single daily report — so you stop logging into three dashboards and reconciling numbers by hand. It also recommends weekly budget shifts across platforms based on blended CPI and downstream retention, not just surface-level cost.
What is a predictive campaign pause model? It's a scoring rule that estimates, from the first hours of a campaign's data, how likely that campaign is to hit your cost-per-install goal. Campaigns that score as high-risk get surfaced for pausing — or paused automatically under an agreed threshold — before they finish burning a full day's budget. It turns "we'll know in three days" into "we know in three hours."
Do I need engineers or a data team to set this up? No. The whole thing started with one plain-English request to analyze six months of data and build the model. Connecting the ad accounts and setting target benchmarks takes no code. Mindra runs the analysis, builds the scoring rule, and delivers the daily alerts. A non-technical growth lead can own it end to end.
Does the AI make spending decisions on its own? Only the small ones you've pre-approved. Auto-pause fires only under a budget threshold the team agreed on in advance, and every automatic action gets reported after the fact. Anything bigger gets a recommendation and waits for a human click — plus a full audit trail of who approved what.
Where Mindra fits
Mindra lets any team hire a whole department of AI agents with a single sentence. The agents act like coworkers: they connect to your tools across 3,000+ integrations, read your data, take actions, run on a schedule, and keep a memory of what's working. Everything runs with human-in-the-loop approvals, full audit trails, RBAC and SSO, and is model-agnostic (Claude, Gemini, GLM, Qwen, DeepSeek). It's SOC 2 Type II and GDPR compliant, with Zero Data Retention available. No engineers required.
For a performance marketing team, that means a tireless growth analyst watching all three ad platforms 24/7 — catching losing campaigns in hours instead of days, keeping creative briefs same-day, and leaving every decision that matters in your hands.
Book a demo and see what your first agent could ship this week.
See more in Mindra case studies. Related reads: How a mobile game studio runs a live competitor ad feed and How a one-person sales team never lets a lead go cold.

Zeynep Yorulmaz
CEO of Mindra
Zeynep Yorulmaz is the Co-Founder & CEO of Mindra, building the platform that lets any team hire a whole department of AI agents with a single prompt.
Stay Updated
Get the latest articles on AI orchestration, multi-agent systems, and automation delivered to your inbox.
Mindra field guide
Read next
Related Articles
How a Mobile Game Studio Turned Competitor Ad Research Into a Live Daily Feed
A 50-person mobile game studio replaced a part-time, hit-or-miss research habit with an AI agent that watches 20+ competitors across four ad networks and delivers a tagged digest every morning.
How a Food Delivery Platform Runs Ops for 3,000+ Restaurant Partners With AI Agents
A national food delivery platform used AI agents to flag failing restaurant partners two weeks early, catch a leaked coupon code in week one, and triage urgent support tickets in minutes.
How a Fintech Cut First-Response Time From 6 Hours to 4 Minutes — Without Lowering the Compliance Bar
A five-person support team was buried in tickets mixing routine questions with sensitive ones. By building an AI support agent around guardrails first, this fintech hit 4-minute first responses and zero compliance violations.
How a One-Person Consultancy Built a Full CRM Out of AI Agents — and Never Let a Lead Go Cold
An independent B2B operations consultant replaced his messy spreadsheet and willpower-driven follow-ups with a CRM made of AI agents — sourcing, scoring, and nurturing 340+ leads into 6 new client engagements in 5 weeks.
How a Two-Person HR Team Runs Onboarding, Policy, and Compliance for 150 People With AI Agents
A two-person HR team supporting 150 employees stopped answering the same PTO and policy questions all day. Here is how they put AI agents to work on the routine and kept judgment human.
How a B2B SaaS Team Catches Churn Risk 3 Weeks Before the Cancellation Email
A B2B SaaS team fused Amplitude, Zendesk, and Stripe data with AI agents to score 940 accounts daily, surface real churn signals 3 weeks early, and save 41% of flagged accounts.